The Lion King(2019) — Plot Summary Analysis Using R

How to conduct text analysis using R
Introduction.
The Lion King (2019) is a movie that has dominated box office charts since its release. Moreover, an interesting music album “The Lion King: The Gift” was released to accompany the 1994 movie remake.
On July 19, 2019, The Lion King(2019 film) was theatrically released in the United States and has grossed over $1 billion worldwide, becoming the fourth highest-grossing film of 2019, the eighth highest-grossing animated film, and the 39th highest-grossing film of all-time. Wikipedia further states that it received mixed reviews, with praise for its visual effects, musical score, and vocal performances but criticism for the lack of originality and facial emotion on the characters. (I leave this for you to decide)
According to imdb.com, Director Jon Favreau’s remake of the animated classic collected a massive $185 million from 4,756 North American theatres during its first three days of release.
The movie landed the best domestic launch for a PG film and set a new record for the month of July. That figure represents the second-best domestic debut of the year behind Disney and Marvel’s “Avengers: Endgame” ($357 million).
The above figures are simply astounding!
In this article, we will conduct a simple text analysis of the movie’s plot using R (Source — https://en.wikipedia.org/wiki/The_Lion_King_(2019_film)).
Below is a snippet of the text data;
Getting Started
1. Loading the Packages
Packages can be installed with the install.packages() function in R.
Load the required libraries using the command below
# Load the librarieslibrary(readr) # reading in the text file
library(wordcloud) # plotting the word cloud
library(tidyverse) # data cleaning and visualization
library(syuzhet) # sentiment analysis
library(tm) # creating corpus
2. Load the data
To access the data, copy and paste the plot in a text file on your computer e.g Notepad.
The file contains text data which is basically the plot summary of the Lion King 2019 movie and we are going to perform various operations on this data.
The read_lines function reads lines from a file.
# Copy paste the Plot summary as a .txt file in your computer# Load the datalion_king <- read_lines("C:/Users/MARGRET/Desktop/Blog/Blog/lion_king.txt")# File sizefile.size("C:/Users/MARGRET/Desktop/Blog/Blog/lion_king.txt")
3. A Few String Operations
# Lengthlength(lion_king)# String operationslion_king <- tolower(lion_king) #lower casenchar(lion_king[1]) # size of each elements of an character vector
Let’s now split the sentences word for word using the strsplit() function. This function is used to split a string into substrings with the specified delimiter(what separates one or more words). In our case, the delimiter is an empty space which in the code is written as “ ”.
# Splitting Word for wordlion_list <- strsplit(lion_king, " ")lion_words <- unlist(lion_list)
We will then remove punctuations such as dots or commas using this command;
The gsub() function in R is a replacement function, which replaces the occurrence of a substring with another substring. Here, we will replace punctuations with an empty space.
# Remove Punctuationlion_words <- gsub("[[:punct:]]", " ", lion_words)
4. Creating a Corpus
A corpus (corpora pl.) is just a format for storing textual data that is used throughout linguistics and text analysis. It usually contains each document or set of text, along with some meta attributes that help describe that document.
The “ tm” package is used to create a corpus from our plot summary.
# create corpus
lion.corpus <- Corpus(VectorSource(lion_words))Some words like a, an and the aren’t relevant for the analysis. Therefore, we will remove them using the removeWords() function.
# clean up by removing stop wordslion.corpus <- tm_map(
lion.corpus,
function(x) removeWords(x, stopwords())
)a <- lion.corpus
Next step is to create a term document matrix.
A term document matrix is a way of representing the words in the text as a table (or matrix) of numbers. The rows of the matrix represent the text responses to be analysed, and the columns of the matrix represent the words from the text that are to be used in the analysis.
# Computing the term document matrix
tdm <- TermDocumentMatrix(a)Transforming our data for a word cloud;
# Transforming data for wordcloudm <- as.matrix(tdm)
v <- sort(rowSums(m), decreasing = TRUE)
myNames <- names(v)
d <- data.frame(word = myNames, freq = v)
5. Creating a WordCloud of the Most Frequently Used Terms
# Making and displaying the wordcloudwordcloud(d$word, d$freq,
random.order = FALSE, colors = brewer.pal(8, "Dark2")
)title(main = "The Lion King 2019", font.main = 2.5, cex.main = 1.5)

As you can see above simba is portrayed as the biggest word. This simply means that it was the most commonly used word in the plot. Mufasa, scar and pride followed.
6. Bar Chart of the Topmost Frequent Words
Let’s create a bar chart of the top most frequently used words. This is sort of like a replica of the Word cloud.
# Bar Chartd %>%
filter(freq >= 4) %>%
mutate(word = reorder(word, freq)) %>%
ggplot(aes(x = word, y = freq, fill = word)) +
geom_col() +
xlab(NULL) +
coord_flip() +
labs(
x = "Count",
y = "Top Words",
title = "Count of top 12 words found in The Lion King 2019 Plot Summary"
) +
theme(legend.position = "none") +
labs(caption = "Data Source: Wikipedia| Plot by maggie_@162880")
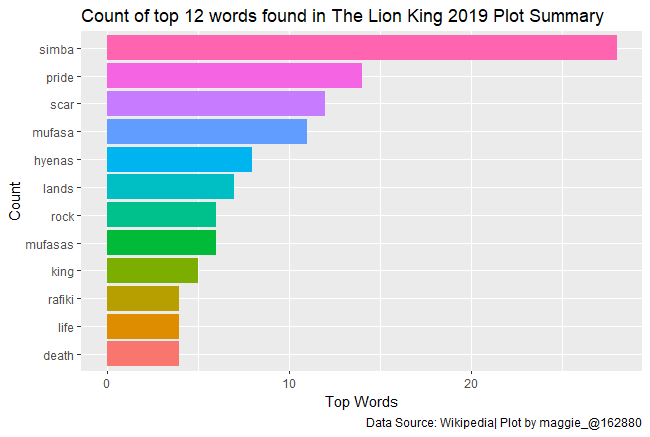
The most commonly used word was simba followed by pride and scar. Rafiki(a kiswahili word meaning friend — English Translation)also came in 10th place followed by life and death.
7. Sentiment Analysis
On checking the string of our data(d), the word variable is a factor with 242 levels. For one to use the sentiment code get_nrc_sentiment() the word variable needs to be a character vector.
Therefore, let’s change that.
# Changing the word from factor to character vectord$word <- as.character(d$word)
The get_nrc_sentiment implements Saif Mohammad’s NRC Emotion lexicon. According to Mohammad, “the NRC emotion lexicon is a list of words and their associations with eight emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and two sentiments (negative and positive)” (See http://www.purl.org/net/NRCemotionlexicon). The get_nrc_sentiment function returns a data frame in which each row represents a sentence from the original file. The columns include one for each emotion type as well as the positive or negative sentiment valence. The example below calls the function using the d object. (our data)
#Get sentimentslionsent <- get_nrc_sentiment(d$word)
Let’s now look at our data again.
# Let's look at the corpus as a whole again:
lion_king_sent <- as.data.frame(colSums(lionsent))
lion_king_sent <- rownames_to_column(lion_king_sent)
colnames(lion_king_sent) <- c("emotion", "count")Plotting the sentiments;
# Plot the sentimentslion_king_sent %>%
mutate(emotion = reorder(emotion, count)) %>%
ggplot(aes(x = emotion, y = count, fill = emotion)) +
geom_bar(stat = "identity") +
theme_minimal() +
theme(legend.position = "none", panel.grid.major = element_blank()) +
labs(x = "Emotion", y = "Total Count") +
ggtitle("Sentiments of The Lion King 2019 Plot Summary") +
theme(plot.title = element_text(hjust = 0.5)) +
theme(axis.text.y = element_text(
face = "bold", color = "#993333",
size = 12, angle = 0
)) +
labs(caption = "Data Source: Wikipedia| Plot by maggie_@162880") +
coord_flip()
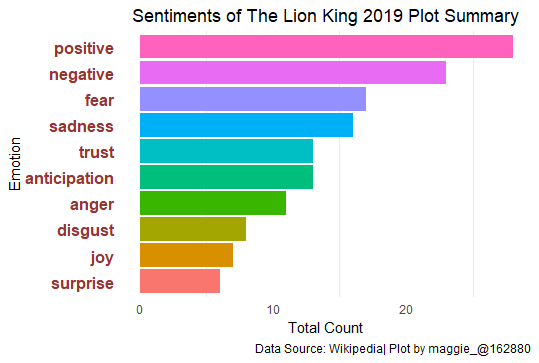
It’s great to see that the plot summary is mostly positive but interesting to see that negative emotions come in second as well. This is a simplified way to figure out what the plot summary emphasized on which could guide one in making quick insights.
Conclusion
The purpose of textual analysis is to describe the content, structure, and functions of the messages contained in texts. This can guide one in gaining insights on what individuals/teams mostly talked about and described in an efficient manner.
For a more understanding of this kind of analysis, check out the following resources/ links;
- https://cran.r-project.org/web/packages/syuzhet/vignettes/syuzhet-vignette.html
- https://www.displayr.com/text-analysis-hooking-up-your-term-document-matrix-to-custom-r-code/
- https://medium.com/@actsusanli/text-mining-is-fun-with-r-35e537b12002
- https://towardsdatascience.com/a-light-introduction-to-text-analysis-in-r-ea291a9865a8
- https://www.displayr.com/text-analysis-hooking-up-your-term-document-matrix-to-custom-r-code/
Thanks for reading.
Feel free to contact me and share feedback on Twitter (https:// https://twitter.com/magwanjiru).
